NVIDIA's NV40 VPU

Hier die technischen Daten im Überblick:
| NVIDIA GeForceFX 5900 (NV35) |
NVIDIA GeForce 6800 (NV40) |
ATi Radeon 9800 (R350) |
|
| Pixel
pro Takt |
4(Farb+Z) / 8(Stencil+Z) | 16(Farb+Z) / 32(Stencil+Z) | 8 |
| Multiple Render Targets (MRT's) | nein |
4 | 4 |
|
Vertex Pipelines
|
1(FP-Array) | 2(FP-Array) | 4 |
| max. Texturen pro Pixel (pro Pass) | 8 | 8 | 8 |
| Speicherinterface (Bit) | 256
DDR |
256 GDDR3 | 256 DDR / DDR II |
| DirectX
Version (Pixel / Vertex Shader) |
DX
9.0 (2.0 Ext. / 2.0 Ext.) |
DX
9.0 (3.0 / 3.0) |
DX
9.0 (2.0 / 2.0) |
| Fließkomma-Texturen
und Render Targets (Blending, Filtering, MipMapping, FSAA) |
sehr eingeschränkt
(via. FourCC METs) (nein, nein, nein, nein) |
ja
(ja(nur FP16), ja(nur FP16), ?, ?)
|
ja
(nein, nein, nein, nein)
|
| Fließkomma-Rechengenauigkeit | 16
oder 32 Bit |
32 Bit | 24
Bit |
| 32/24 Bit Modus langsamer als 16 Bit Modus | ja | nein | nein |
| max.
anisotrophes Filtern |
8 |
16 |
16 |
| Bandbreiten Features | Intellisample
3.0: Textur-,
Z- und Farbwertekompression UltraShadow 1.0: Depth Bounds und doppelte Füllrate(Stencil+Z) |
Intellisample
3.0: Textur-,
Z- und Farbwertekompression, UltraShadow 2.0: Depth Bounds und doppelte Füllrate(Stencil+Z) |
HyperZ
III: Textur-,
Z- und Farbwertekompression, |
| FSAA | 2x
- 8x Multi-Sampling (teilw. mit Super-Sampling gemischt) Ordered Grid FSAA ohne Gammakorrektur |
2x
- 8x Multi-Sampling (teilw. mit Super-Sampling gemischt) Ordered Grid FSAA und Rotated Grid FSAA ohne Gammakorrektur |
2 -
6 SubPixel Multi-Sampling Rotated Grid FSAA mit Gammakorrektur |
Features im Überblick:

Pixel Shader 3.0
Vergleichen wir hier die Pixel Shader Pipelines der verschiedenen VPU:
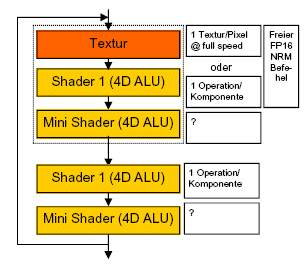
NV35 - 4 Pipelines
sobald mit Texturbefehlen gearbeitet wird, sinkt die Arithmetikleistung des NV35
R350 - 8 Pipelines
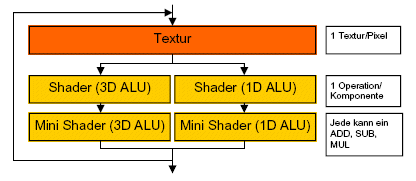
vor allem die Paarung in Vector(3D) und Scalar(1D) bringt beim R350 Vorteile
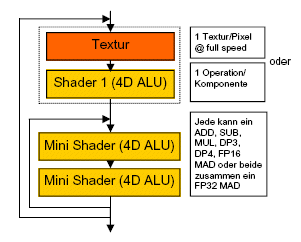
NV40 - 16 Pipelines
deutlicher Vorteil für den NV40 gegenüber dem NV35, selbst mit Texturbefehlen steht die Arithmetikleistung der NV35-Pipeline zur Verfügung, ohne fast die doppelte und immer kann ein nrm_pp ausgeführt werden
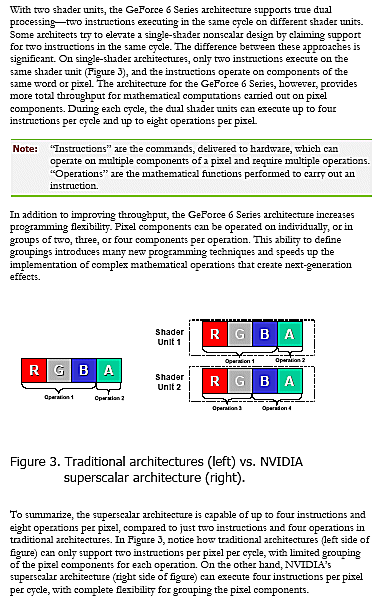
Zusätzlich scheint die Anordnung der einzelnen Komponenten bzw. deren Gruppierung keinen Einfluss mehr auf die Effizienz der Pixel Shader zu haben. Beim R350 sollte noch darauf geachtet werden, möglichst 3D und 1D Operationen zu paaren, um diese per "Co-Issue" (Zusammenfassung) in einem Taktzyklus ausführen zu können. Somit kann der NV40 im besten Falle bis zu 4 Intruktionen pro Takt Pro Pipeline Ausführen.
float4 Diffuse_Beleuchtung( PS_INPUT IN ) : COLOR
{
float3 Normal = normalize(IN.Norm);
float3 ViewDir = normalize(IN.View);
// R = ambient + diffuse (N dot L) - L
float3 Ct = tex2D(BaseMap, IN.Tex);
float N_L=saturate(dot(IN.Light, Normal));
// ambient part
float3 color = Ct * Ka;
if(N_L>0.0f) // diffuse part visible ?
{
// diffuse part
color = color + Ct * Dx * Kd * N_L;
}
return float4(color, 1.0);
}
Hier könnte "Branching" die Berechnung des diffussen Anteils überspringen, wenn N_L = 0.0 ist.
// Default values:
//
// Dx
// c0 = { 1, 1, 1, 1 };
//
// Ka
// c1 = { 0.0125, 0, 0, 0 };
//
// Kd
// c2 = { 1, 0, 0, 0 };
//
ps_2_0
def c3, 1, 0, 0, 0
dcl t1.xyz
dcl t0.xy
dcl t2.xyz
dcl_2d s0
texld r0, t0, s0
mul r1.xyz, r0, c0
mul r0.xyz, r0, c1.x
mul r1.xyz, r1, c2.x
nrm r2.xyz, t1
dp3_sat r2.x, t2, r2
mad r1.xyz, r1, r2.x, r0
cmp r0.xyz, -r2.x, r0, r1
mov r0.w, c3.x
mov oC0, r0
// approximately 12 instruction slots used (1 texture, 11 arithmetic)
ps_2_0 können kein Branching, wie man hier deutlich sieht. Es werden immer die gleichen Befehle ausgeführt, egal welchen Wert N_L hat.
// Default values:
//
// Dx
// c0 = { 1, 1, 1, 1 };
//
// Ka
// c1 = { 0.0125, 0, 0, 0 };
//
// Kd
// c2 = { 1, 0, 0, 0 };
//
ps_3_0
def c3, 1, 0, 0, 0
dcl_texcoord1 v0.xyz
dcl_texcoord v1.xy
dcl_texcoord2 v2.xyz
dcl_2d s0
texld r0, v1, s0
mul r1.xyz, r0, c0
mul r0.xyz, r0, c1.x
nrm r2.xyz, v0
mul r1.xyz, r1, c2.x
dp3_sat r0.w, v2, r2
mad r1.xyz, r1, r0.w, r0
cmp oC0.xyz, -r0.w, r0, r1
mov oC0.w, c3.x
// approximately 11 instruction slots used (1 texture, 10 arithmetic)
ps_3_0 können Branching, jedoch ist der momentan aktuellste beta HLSL-Compiler nicht in der Lage, "Branching" einzubauen, doch dies sollte sich bis zum Sommer 2004 ändern, dann dürften auch VS/PS3.0 fähige Treiber für die NV40 vorliegen!
Wie auch schon ATi's R3xx unterstützt der NV40 4 MRTs.
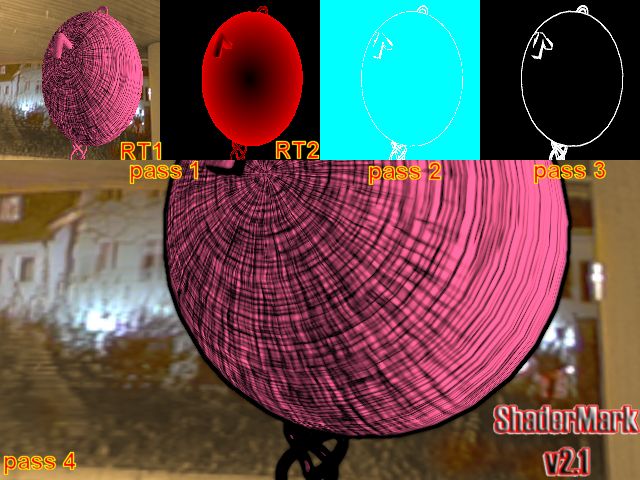
hier wird z.B. im "pass 1" gleichzeitig in das Render Target
1 und 2 geschrieben, welche später in "pass 2", "pass 3" und "pass 4" verwendet werden
NVIDIA HIGH-PRECISION DYNAMIC-RANGE (HPDR) TECHNOLOGY


ohne Filterung mit Filterung
Vertex Shader 3.0

Einziger Nachteil, welchen erst die 4.0'er Shader beheben, man kann keine Eckpunkte im Vertex Shader erzeugen, somit braucht man hochauflösende 3D-Geometrie, welche man dann "verformen" kann.

Das Problem: Je weniger Vertexdaten mir pro DirectX API-Aufruf and die Grafikkarte gesendet werden, umso größer die CPU Abhängigkeit einer Anwendung, denn API-Aufrufe werden von der CPU bearbeitet, Vertexdaten von der VPU.
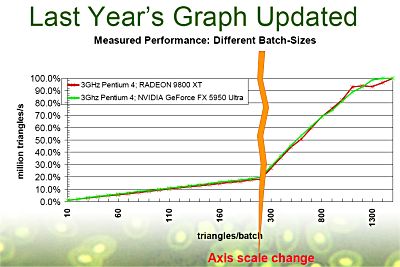
Momentane Lösung: "Batching". Es werden soviele Vertexdaten wie möglich in einen Vertexpuffer gepackt und dann in einem API-Aufruf an die Grafikkarte gesendet. Ähnlich verhält es sich mit anderen API-Aufrufen, welche andere Parameter, Texturen und Shader zuweisen - hier soll es aber nur um Vertexdaten gehen!
Neuer Lösungsweg:

2 Vertexpuffer, einer enthält das 3D-Modell, der anderen nur veränderliche Daten, wie z.B. die Transformationsmatrizen etc.

Durch die Festlegung der Vertex Stream Frequency ist es nun einfach möglich 100 Bäume zeichnen zu lassen.
Die 3D-Daten des Baumes werden einmal, die wesentlich kleineren Transformationsmatrizen 100 mal zum Vertex Shader gesendet - dies alles mit nur einem einzigen API-Aufruf, statt der üblichen 100, welche zusätzlich auch noch mehr Daten zur Grafikkarte transportieren müssten.
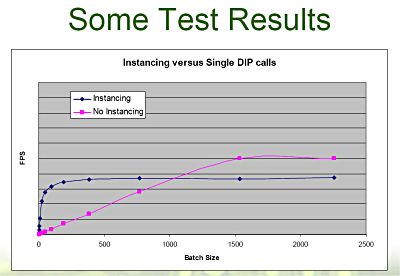
Das Resultat kann sich sehen lassen, gerade bei keinen "Batch" Größen, welche recht häufig vorkommen
Vorteile:
- geringere CPU Belastung
- effizientere VPU Auslastung
- geringere Busbelastung (AGP, PCI Express)
FSAA
Über die FSAA Fähigkeiten des NV40 ist zur Zeit recht wenig bekannt. So wie es aussieht, kann der NV40 die selben Modi wie der NV35, zusätzlich jedoch einen 4x FSAA Modus mit rotiertem Gitternetz. Hier könnte der R3xx noch leichte Vorteile dank seiner Gammakorrektur haben, dies muss aber ein Review klären!
Video Verarbeitung
Hier gibt es auch einige Neuerungen gegenüber dem
NV35. Der NV40 kann hier mit MPEG2/4, WMV9 und DivX Kodierung und
Dekodierung aufwareten!
Die Karte


Zwei Molex-Anschlüsse, welche laut NVIDIA mit einem 450 Watt (besser 480) Netzteil betrieben werden sollten, zwei DVI-Ausgänge und einem Kühlkörper, welcher hoffentlich nur einen Slot belegt - so schaut die GeForce 6800 aus.